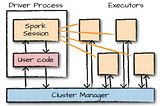
PinnedHow to determine Executor Core, Memory and Size for a Spark appI am assuming that you are familiar with basics of Spark programming and trying to optimize Spark for better resource management.Jun 1, 20222Jun 1, 20222
PinnedClustering Technique for Categorical Data in pythonk-modes is used for clustering categorical variables. It defines clusters based on the number of matching categories between data points…Apr 4, 2021Apr 4, 2021
All you need to know about password storage in a Django application (Encryption or Hash)?IntroductionMar 26Mar 26
Memory Management in Apache SparkSpark’s performance advantage over MapReduce is greatest in use cases involving repeated computations. Much of this performance increase is…Mar 22Mar 22
How do we find all the workflow that has interim results turned on in Adobe Campaign Classic?Well in the ‘xtk’ namespace we can find a schema named ‘Workflows’Mar 21Mar 21
Incremental Data Loading with Apache Spark concept with special Parquet file feature of increment…There are two type of Data LoadingJul 8, 20222Jul 8, 20222
Why is Spark 10x faster on disk than Hadoop MapReduce?All there are plenty of differences the way MapReduce and Spark works but we are going to see some of themJul 7, 2022Jul 7, 2022
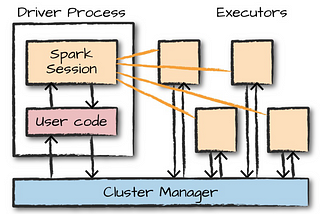
What happens when you submit a Spark application?When we submit a spark application using spark-submit scriptJul 3, 2022Jul 3, 2022
Garbage Collection Tuning Concepts in SparkAll though Memory Management is a fairly vast concept and there are many ways we try to mitigate it but we would talk about it in very…Jun 29, 20221Jun 29, 20221